Frequently Asked Questions
What is Plagiarism Detector?
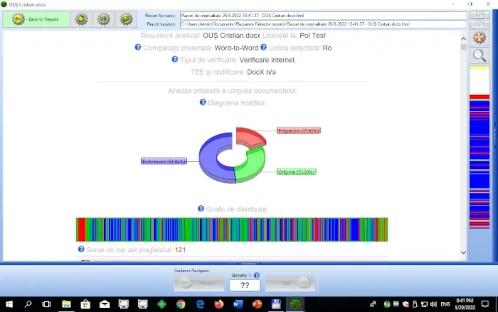
Plagiarism Detector is a desktop plagiarism checking software for Windows that scans documents against billions of online sources, the ScIPaP academic paper database, and a private PDAS document accumulator to identify copied, paraphrased, and AI-generated content. It supports 12+ file formats including DOC, DOCX, PDF, and TXT, and generates detailed Originality Reports with similarity percentages, highlighted matches, and clickable source URLs.
How does Plagiarism Detector work?
Plagiarism Detector works by extracting text from your documents and comparing it against five search engines — Google, Bing, Yahoo, DuckDuckGo, and the ScIPaP academic paper database — to find matching content across over 4 billion web pages. The software uses advanced fingerprinting algorithms to detect exact matches, paraphrased passages, and mosaic plagiarism, then generates an Originality Report that highlights every matched segment with its source URL and similarity score.
Is Plagiarism Detector free?
Plagiarism Detector offers a free demo download that lets you test all features with limited document checks. Full licenses — Lite, Personal, Pro, and Portable — are one-time purchases starting at $49 with no monthly or annual subscription fees. Every license includes lifetime access to minor updates, the UACE Anti-Cheating Engine, AI Content Detector, and multi-format document support.
What makes Plagiarism Detector different from online checkers?
Unlike online plagiarism checkers, Plagiarism Detector runs entirely on your desktop, so documents never leave your computer — ensuring complete privacy and data security. It checks against five search engines simultaneously instead of one, includes offline Document Pair Comparison, accumulates results in a local PDAS database for cross-reference checking, and provides the UACE Anti-Cheating Engine that detects Unicode character substitution tricks that web-based tools miss.
Does Plagiarism Detector detect AI-generated content?
Yes. Plagiarism Detector includes a built-in AI Content Detector that identifies text generated by ChatGPT, GPT-4, Claude, Gemini, and other large language models. AI detection runs automatically alongside every plagiarism check in a single scan, so you get both plagiarism and AI-generated content results without needing a separate tool or paying an additional fee.



 Stand with Ukraine!
Stand with Ukraine!













 Internet (Google & Bing) + SciPap DB
Internet (Google & Bing) + SciPap DB
 Our Scientific Papers DB Check: SciPap
Our Scientific Papers DB Check: SciPap
![Your Custom DB Check [via PDAS add-in]](/img/ct-database.svg) Your Custom DB Check [via PDAS add-in]
Your Custom DB Check [via PDAS add-in]
 Your Local Folder of Documents Check
Your Local Folder of Documents Check
 A Document Pair Check
A Document Pair Check
 Combined (Hybrid) Sources Check
Combined (Hybrid) Sources Check
































